






Pokud si chcete osvěžit dosavadní znalosti o regulárech nebo vám některý z předchozích dílů unikl, mrkněte se na jednotlivé články – 1. díl, 2. díl, 3. díl.
Užitečné značky pro regulární výrazy
Při představování jednotlivých značek jsem vynechal ještě dvě důležité a šikovné — \D a \S. Teď to napravím:
- \D funguje jako negace malého \d, tedy vyhledá všechny znaky, které nejsou číslem a je tedy ekvivalentní výrazu, který jsem představil minule — [^\d]
- \S potom vyhledává takové znaky, které nepatří mezi bílé, tedy nejde o mezery, tabulátory, nové řádky apod., taktéž je ekvivalentní výrazu z minula — [^\s]
Pro přehlednost ještě přidávám tabulku všech značek, které v příkladech používám.
| REGULÁRNÍ VÝRAZ | VYHLEDÁ |
| . tečka | právě jeden neznámý znak |
| * hvězdička | konkrétní znak 0 až nekonečně krát |
| ? otazník | konkrétní znak 0 nebo 1 krát (znak se nevyskytuje nebo vyskytuje jen jednou) |
| + plus | konkrétní znak 1 až nekonečně krát (znak se vyskytuje alespoň jednou) |
| [] hranaté závorky | jeden ze skupiny hledaných znaků |
| {} složené závorky | x opakování znaku nebo skupiny znaků před závorkou |
| ^ stříška | od začátku řetězce |
| $ dolar | od konce řetězce |
| | svislítko | jeden NEBO druhý znak (česky nebo) |
| \s | mezeru a další bílé znaky (tabulátory, nové řádky) |
| \d | zastupuje čísla od 0 do 9 |
| \S nebo [^\s] | cokoli kromě bílých znaků, tedy čísla a písmena (negace \s) |
| \D nebo [^\d] | cokoli kromě čísel, tedy bílé znaky a písmena (negace \d) |
Složitější příklady
A teď ty avizované složitější příklady. Na některé jste se nás ptali na fóru, o jiných si myslím, že je regulární výrazy elegantně řeší.
Přepsání informace z jednoho elementu do druhého
Častým nedostatkem feedů jsou chybějící nebo špatně naplněné elementy. Podobně často se požadovaná informace vyskytuje na jiném místě ve vašem kódu a je tedy logickým řešením ji odtamtud přepsat do správného elementu. Nejprve je nutné zkontrolovat, že takový element náš feed obsahuje a pokud ne, tak ho na stránce Elementy doplnit. Zároveň předpokládejme, že se tento problém týká více než dvou desítek produktů (jinak by bylo snazší řešit jej ručně). Chceme proto zautomatizovat přepisování tak, aby Mergado poznalo, kde má informaci vzít. Podívejme se na to pomocí příkladu:
- Naším záměrem je naplnit element MANUFACTURER informacemi o výrobci, která se nachází na začátku PRODUCTNAME.
- V prvním kroku tak vytvoříme proměnnou s názvem MANUFACTURER, jejíž náplní bude první slovo z elementu PRODUCTNAME. (Novou proměnnou přidáte na stránce Proměnné v levém menu skrze příkaz Upravit proměnné).
- To zařídíme skrze regulární výraz: ^\S+ Tento regulární výraz hledá od začátku řetězce jakékoliv znaky do první mezery, najde tedy první slovo v řetězci, a je proto použitelný pro jednoslovné názvy výrobců, např. Addidas, Nike, Reebok, atd.
- Tuto proměnnou potom vložíme pomocí pravidla Přepsat do elementu MANUFACTURER.
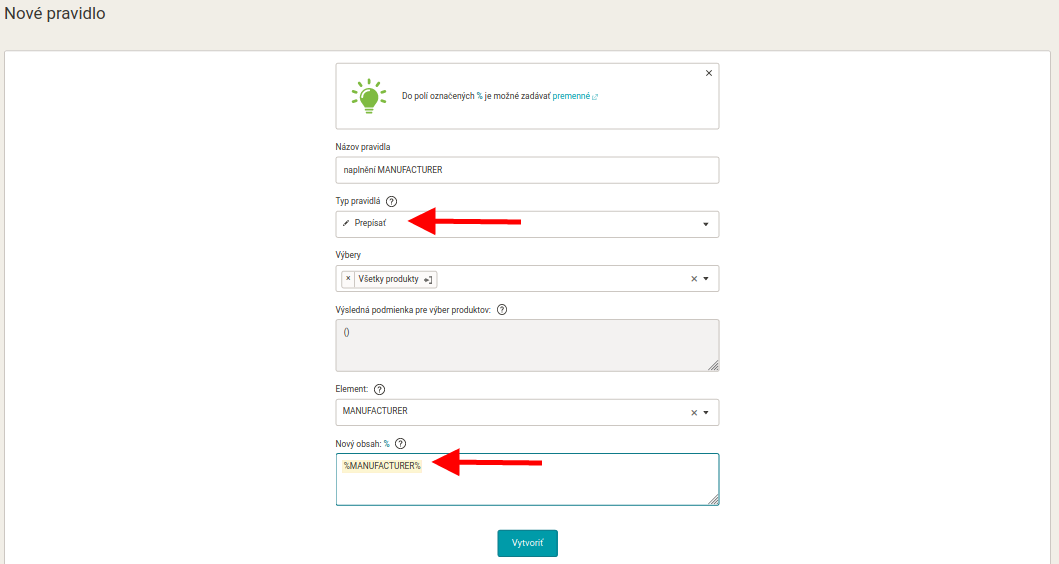
Obdobně můžeme postupovat i u vyhledávání na jiném místě v konkrétním elementu:
- první slovo v textu ^\S+
- první dvě slova od začátku textu ^(\s*\S+){2}
- poslední slovo na konci textu, včetně případné interpunkce na konci \S+$
- poslední dvě slova na konci textu, včetně případné interpunkce na konci (\S+\s*){2}$
Duplicitní slova v elementu
Chceme-li najít duplicitní slova v jednom elementu, můžeme také využít regulární výrazy. Poslouží nám pro zpětnou kontrolu dat, a pravidel, která jsme pro jejich správu nastavili. Například chceme vyhledat duplicity v PRODUCTNAME, můžeme takové produkty vyhledat pomocí regulárního výrazu: (\S+)(.*)\1 Zjednodušeně tímto příklazem Mergadu říkáme: najdi řetězec znaků (např. slovo), za kterým je libovolný text a následně se taková skupina znaků (tedy např. to slovo) znovu opakuje. Výraz nebere ohled na interpunkci, najde tedy výrazy, za kterými je čárka i tečka a zároveň i výrazy bez těchto znamének. Důležité je zmínit, že jde o zjednodušený příklad a takový regulární výraz nebude vyhovovat všem kombinacím, které mohou v textu nastat. Pro naše účely použití v Mergadu však myslím postačí. V případě, že duplicity skutečně najdete, vyplatí se podívat do pravidel, jakým způsobem se nám tam dostaly (mohla to způsobit například opakující se pravidla). Pokud máte jakékoli další dotazy k regulárním výrazům nebo Mergadu obecně, ozvěte se nám do komentářů, do fóra nebo přímo na podpor
Sledujte i další díl Jak na regulární výrazy v Mergadu nebo závěr seriálu o regulárních výrazech.


